Disco4D: Disentangled 4D Human Generation and Animation from a Single Image
CVPR 2025
Hui En Pang1, Shuai Liu, Zhongang Cai2, Lei Yang2, Tianwei Zhang1, Ziwei Liu1,
1 S-Lab, Nanyang Technological University 2 SenseTime
Abstract
We present Disco4D, a novel Gaussian Splatting framework for 4D human genera- tion and animation from a single image. Different from existing methods, Disco4D distinctively disentangles clothings (with Gaussian models) from the human body (with SMPL-X model), significantly enhancing the generation details and flexibility. It has the following technical innovations. 1) Disco4D learns to efficiently fit the clothing Gaussians over the SMPL-X Gaussians. 2) It adopts diffusion models to enhance the 3D generation process, e.g., modeling occluded parts not visible in the input image. 3) It learns an identity encoding for each clothing Gaussian to facilitate the separation and extraction of clothing assets. Furthermore, Disco4D naturally supports 4D human animation with vivid dynamics. Extensive experiments demonstrate the superiority of Disco4D on 4D human generation and animation tasks.
Image-to-4D
We can support generation and disentanglement.
We can support animation. Diverse 3D motions can be generated for the same static model.
We can support fine-grained editing and composition.
Video-to-4D
Comparisons to Video-to-3D/4D methods
We can support addition of clothing dynamics if more frames are available. We added comparisons to DreamGaussian4D, GaussianAvatar, GART, MonoHuman. Swipe right for the canonical reconstruction.
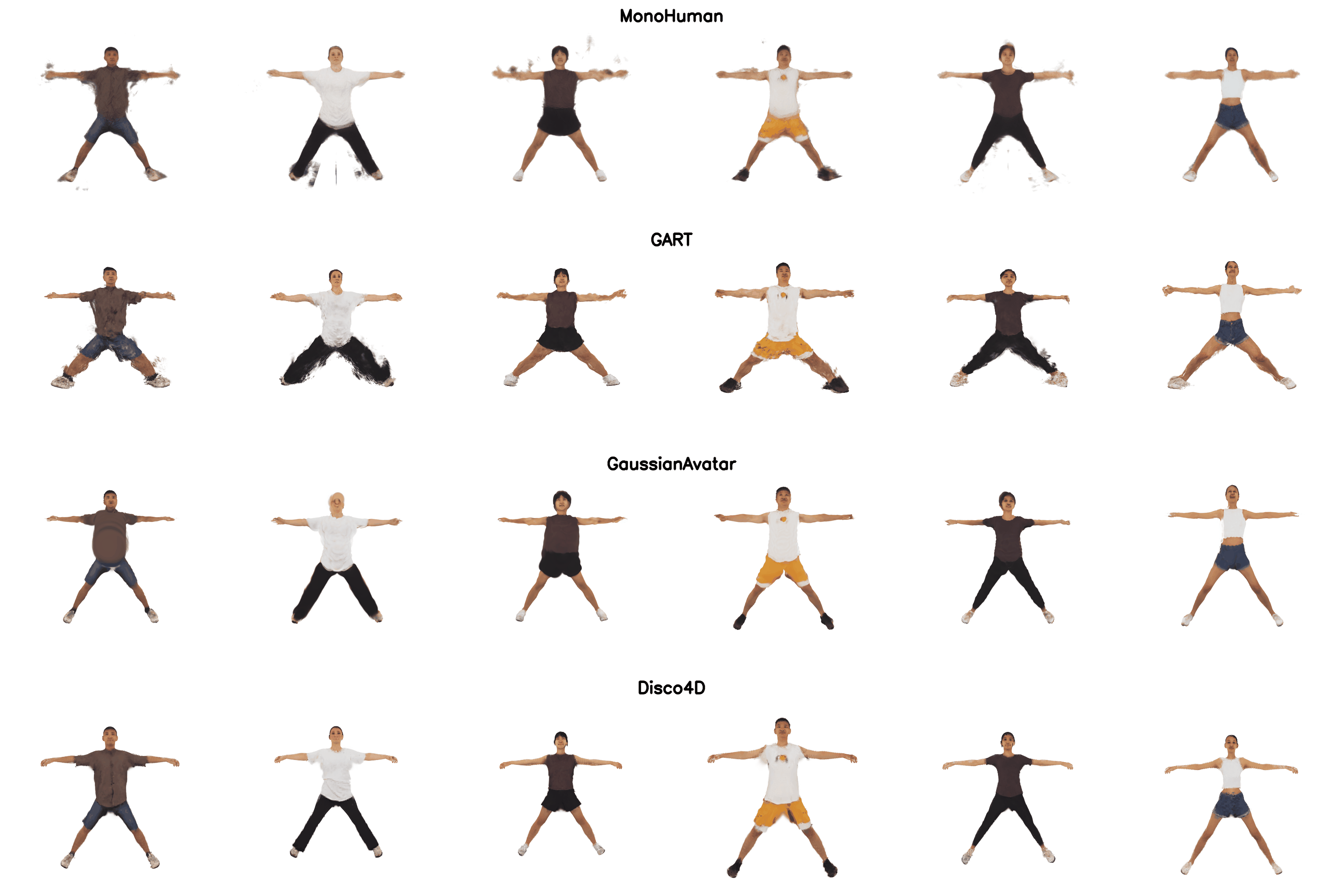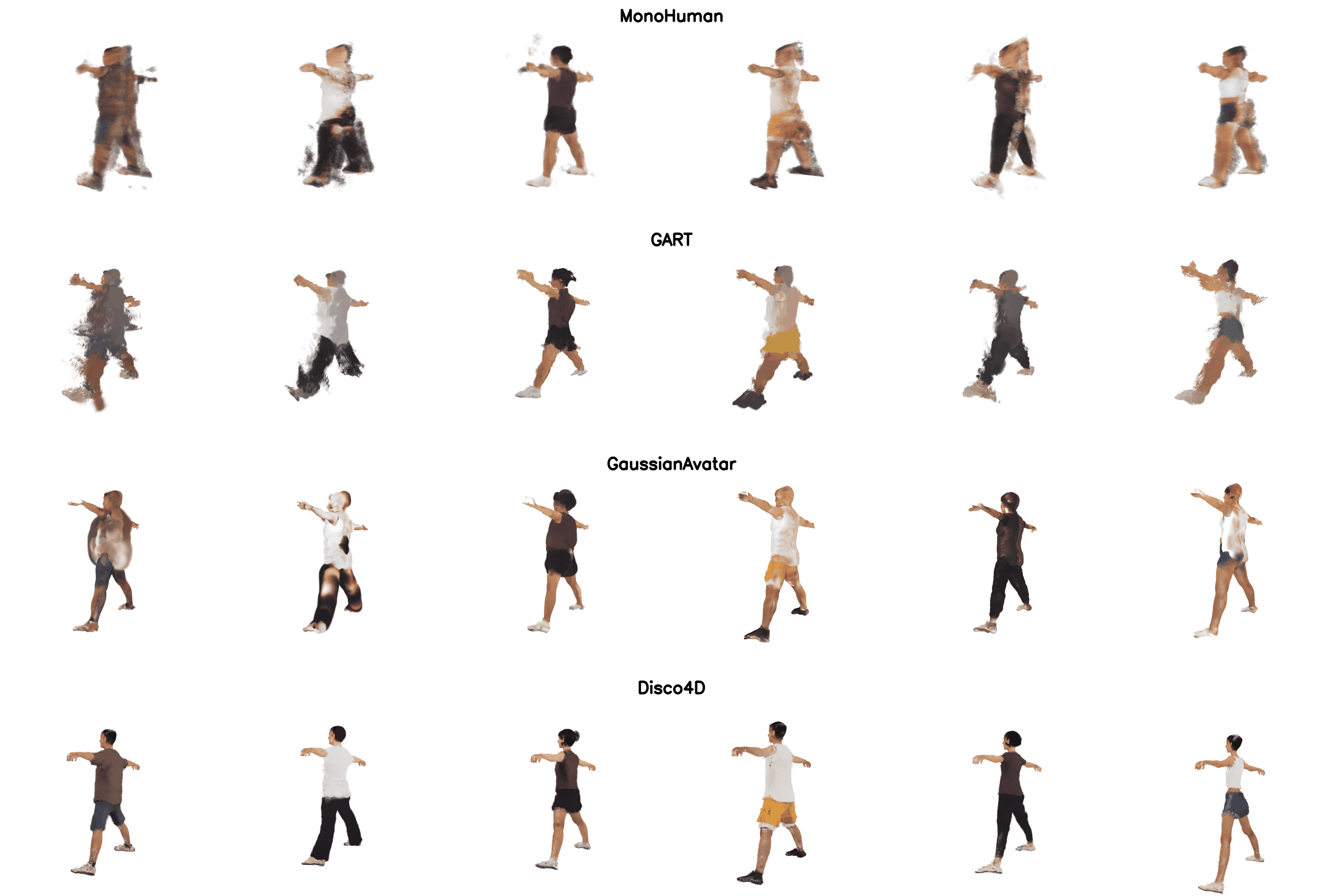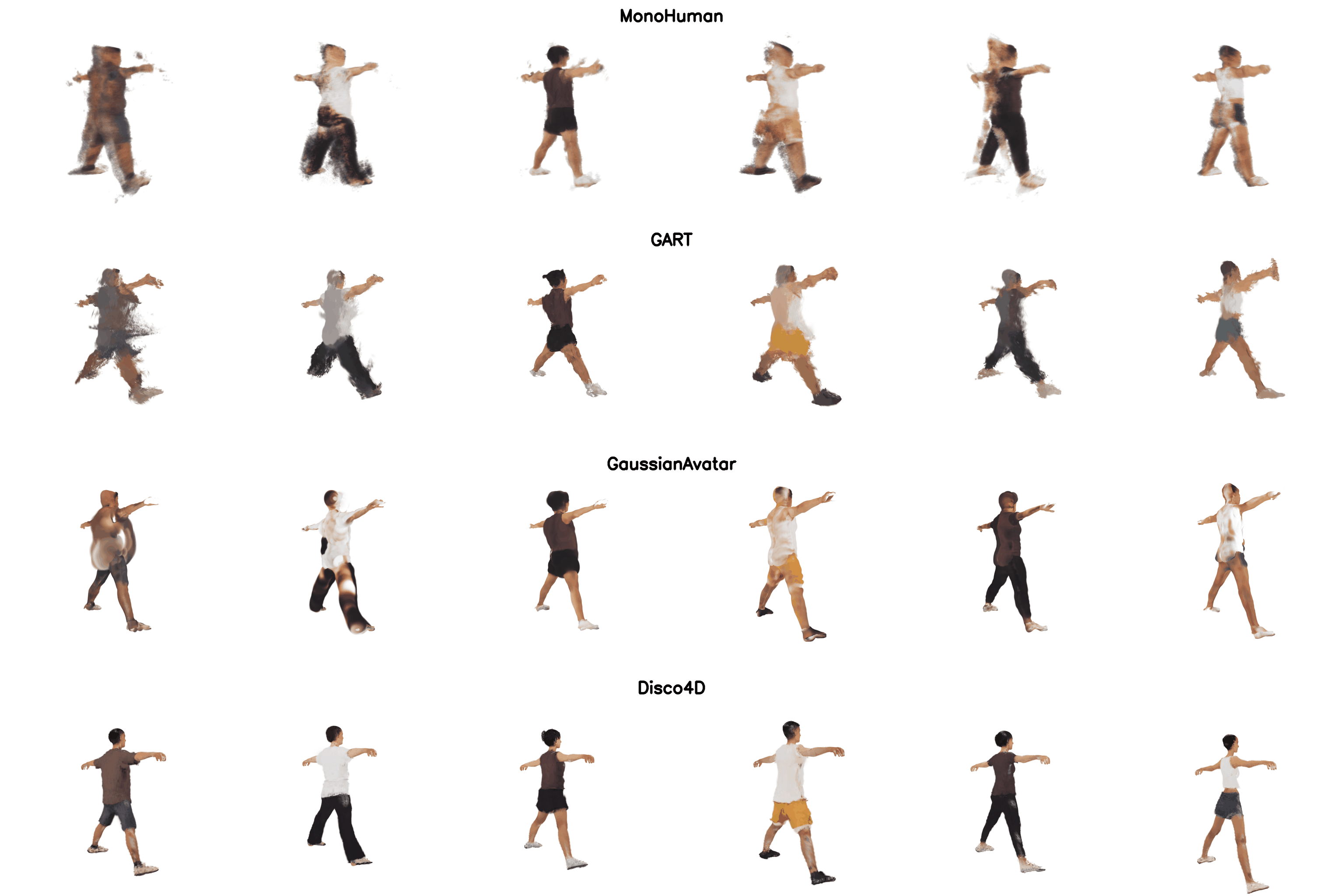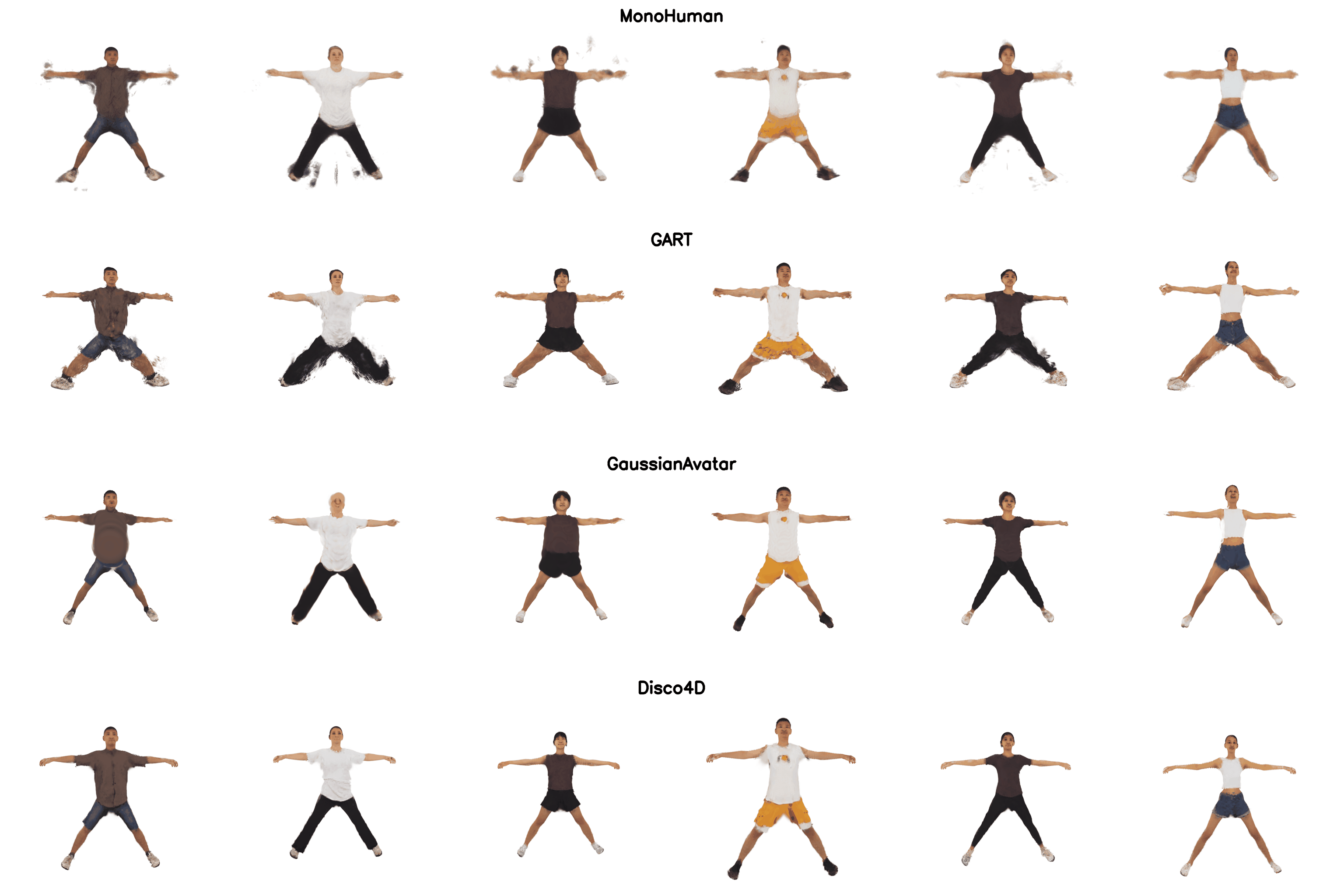
Training data for existing Video-to-4D methods
Existing Video-to-4D method rely on information available from dense multi-view images for reconstruction and are unable to model unseen views.


Citation
@inproceedings{
title={Disco4D: Disentangled 4D Human Generation and Animation from a Single Image},
author={Pang, Hui En and Liu, Shuai and Cai, Zhongang and Yang, Lei and Zhang, Tianwei and Liu, Ziwei},
booktitle={CVPR},
year={2025}
}